I was lucky enough to spend last week at I/ITSEC courtesy of Improbable where we were demonstrating our ASMSW Social Media Synthetic Wrap integrated with their Skyral system, and through that to VBS4, Montvieux's ASAIR and several other systems. Neat demo which drew a good crowd every time. Here are a couple of closer shots of the actual demo (our app top right in both).
In between the demos I had plenty of time to tour the hall and look at the other stands, although I couldn't get into any of the presentations being on an Exhibitor pass.
I must admit to being a bit underwhelmed by what I saw. Almost every stand had VR goggles, mostly high-end ones, or big screens, so this wasn't "accessible" kit, but being sold to defence organisations with big bucks. Despite some bias I think the Improbable offering was actually one of the more interesting and innovative, having a simulation that simultaneously linked the social media and other interactions of a ~250k population with the subjective experience of being in a riot that was driving and being driven by the larger social media response.
Anyway, here are my key takeaways form the show, and I've tried to group the key ones by themes.
Headsets
A good chance to play with the latest headsets from HTC and Varjo. With the Varjo XR-3 in particular ($6495!) you could see the difference in fidelity against the Oculus Quest, and control panel on the training aircraft were crystal clear. With the HTC the posters on the IED trainer I was using were a bit more blurry, but probably better than the Quest. Neither as comfortable as the Quest.
Gloves
The HaptX gloves were on two stands. I only tried the older version. I hadn't appreciated that they were compressed air driven and needed a big floor mounted compressor (backpack in Mk 2) so not really very portable/domestic friendly. I also hadn't appreciated that since they were just air driven there was no hard-stop when touching a surface in the same way that old haptic stylus and controllers could be. The surgery demo was so-so, perhaps the gloves weren't well set-up, but the kids play farm was very good. When you "touched" something you felt enough feedback to say there was something there, but not enough to stop you pushing through. Holding your palm flat up and feeling raindrops under a cloud gave you a sense of the more delicate aspect of touch which, when combined with an animated fox prancing on your hand and the "feel" of her feet was very good and really heightened the immersion.


The telling moment though was when I shut my eyes (in VR!) and found that I could interact with the scene purely by touch, reaching out, picking up an object (closing my hands til feedback), moving the object (making sure I still had the pressure so I knew I hadn't dropped it), and then releasing it (confirmed by loss of pressure). The demonstrator said that in research they'd found that although we use our eyes for gross movements (e.g. put hand near coffee cup or aircraft control) we often then look away at something else and use touch to guide the final stages and then ,make the action. This neat demo proved that that was possible in VR.
I also tried out a more mechanical handset with control wires that gave a firmer touch response, but still not blocking, and just looked a bit Heath-Robinson at the moment.
Building Modelling
The closest to a "wow" moment was probably the companies showing how they could take oblique aerial/orbital photography of a city and then rather than do direct photogrammetry renders (which tend to have rounded corners and look very blurred at street level, so little use for tactical ground combat) were using AI to work out what sort of building it was and then working essentially with a library of building types to re-render it as a proper 3D model. Very neat. Presagis and Blackshark.ai were the stars here.
Avatars
The avatars on show in the apps range from pretty dreadful to OK, nothing really stunning. Here was a nice "life-size" avatar though, nicely animated and probably coming to (or already in) an NHS A&E department near you.
Non-Visual Modelling
Only one company I saw was really showing non-visual modelling, so for instance modelling RF and IR emissions in order to present more of a multi-spectral world - JRM technologies.
Mixed Reality
As well as the VR headsets, both of the main MR headsets were in evidence. Both were underwhelming. With the Hololens 2 I was able to look at an F16 (?) that was "parked" in the exhibition hall (and crushing several stands!). But the FOV really isn't much of an improvement on the Hololens Mk1 and it was impossible to get far enough back to see the whole plane in one go.
I had a good demo of the Magic Leap, showing an "Avatar" style 3D terrain model floating in space between us. If felt like a wider FOV, and being able to peer at the detail at ground level was really cool. BUT, the whole experience was very dark, so dark that I couldn't even see the hands of the demonstrator, so next to useless to work collaboratively pointing out different details. I assume its that they need either low ambient lighting (as in a hangar) or to filter the ambient light (as here) in order to get enough contrast with the projected image. The experience would have been a lot more effectively complete in VR.
Small Controllers
Lots and lots of pistols and automatic rifles instrumented to work as VR controllers, with room space tracking so you could practice your CQB drills. Queues were always too long to try out! There were also (appropriately) lots of medical mannequins around, some connected to VR, to allow you to practice the first aid afterwards.
Big Controllers
Of course the big draws at I/ITSEC were the "big" controllers: tanks, aircraft, helicopters, boats - you name it. Some used big/multiple screens and others used VR. Here are a few.
 |
| A "flappy bird" - reminiscent of an early UCL? VR experience |
Other Cool Stuff
And some other things that caught my eye.
 |
| Best company name ever |
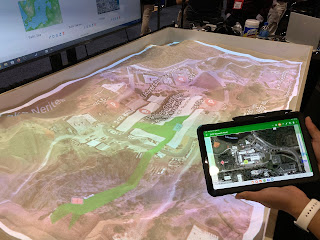 |
| US Army's augmented sandtable - always a great idea and demo |
 |
| The robot-target, filling the A in LVCA. |
Also the latest neuro-tech and physio-monitoring rig from Galea.
The Metaverse
There were about 17 companies (including Improbable) who listed or presented themselves as "metaverse" companies, and I'm sure that almost every salesperson would have been happy in discussion to call themselves the same. Quite honestly none of them were about the Metaverse as I understand it, and just as AI is being blurred beyond usefulness so too we were seeing metaverse being associated with almost anything that included a VR headset, and some which didn't even have that.
Conclusion
As I said at the top, overall underwhelmed. Just far too much "me too" when it came to VR-HMD based systems and not a lot of innovate thinking seems to be going on, and not a lot of democratisation (despite some "no code" vendors). Unlikely to ever go again, cost and time (but writing time by the pool was nice), but glad to have been and perhaps CES would give more of a future wow (but there again perhaps not).
























